GTalk翻译机器人再次升级并带来命令行版
好吧,终于升级到0.3了,我想这个翻译机器人该有的功能也够了,没有什么意外,应该就是最终版了,现在这个机器人拥有原来功能的情况下,由于使用了查询单个英文时用dict.youdao.com进行翻译,而不是原来的fanyi.youdao.com,所以相当于词汇量大增,并且能返回更为详细的信息。
以前添加了dict-icyomik@appspot.com机器人的同学不用再重新添加,新版本已经上传至GAE并生效,下面截图来记念:
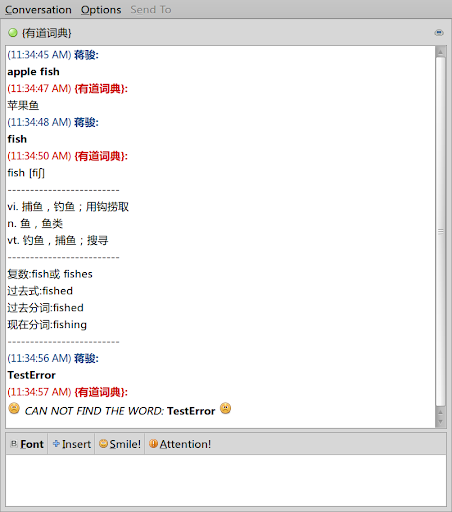
下面的是命令行版本的翻译程序,修改自http://yodao-free.sourceforge.net/程序,感谢David和Boyi的贡献,如果有时间,我可能会将下面的程序写成GUI版的,前提是我有这个无聊的心情和时间。
使用方法是:python youdao.py WORD
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Project 'youdao.py' By:
# iCyOMiK(蒋骏): http://icyomik.tk/
# David and Boyi: http://yodao-free.sourceforge.net/
import re, sys, urllib2
textre = re.compile("\!\[CDATA\[(.*?)\]\]", re.DOTALL)
def get_elements_by_path(xml, elem):
if type(xml) == type(''):
xml = [xml]
if type(elem) == type(''):
elem = elem.split('/')
if (len(xml) == 0):
return []
elif (len(elem) == 0):
return xml
elif (len(elem) == 1):
result = []
for item in xml:
result += get_elements(item, elem[0])
return result
else:
subitems = []
for item in xml:
subitems += get_elements(item, elem[0])
return get_elements_by_path(subitems, elem[1:])
def get_elements(xml, elem):
p = re.compile("<" + elem + ">" + "(.*?)</" + elem + ">", re.DOTALL)
it = p.finditer(xml)
result = []
for m in it:
result.append(m.group(1))
return result
def get_text(xml):
match = re.search(textre, xml)
if not match:
return xml
return match.group(1)
def print_all(xml):
results = ''
asterisk = '*' * 25
return_phrase = get_elements(xml, "return-phrase")
if return_phrase == []:
print '***', 'CAN NOT FIND THE WORD:', \
get_text(get_elements(xml, "original-query")[0]), '***'
sys.exit()
return_phrase = get_text(return_phrase[0])
phonetic_symbol = get_elements(xml, "phonetic-symbol")
phonetic_symbol = get_text(phonetic_symbol[0])
results = return_phrase + ' [' + phonetic_symbol + '] ' + '\n'
custom_translations = get_elements(xml, "custom-translation")
for cus in custom_translations:
if get_text(get_elements(cus, "type")[0]) == 'ee':
break
contents = get_elements_by_path(cus, "translation/content")
if contents:
results = results + asterisk + '\n'
for content in contents[0:]:
results = results + get_text(content) + '\n'
for cus in custom_translations:
contents = get_elements_by_path(cus, "word-forms/word-form")
if contents:
results = results + asterisk + '\n'
for content in contents[0:]:
results = results + get_text(get_elements(content, 'name')[0]) \
+ ':' + get_text(get_elements(content, 'value')[0]) + '\n'
results = results + asterisk
print results.strip()
if __name__ == '__main__':
if len(sys.argv) < 2:
print './youdao.py *'
sys.exit()
xml = urllib2.urlopen("http://dict.yodao.com/search?doctype=xml&xmlDetail=true&q=" \
+ urllib2.quote(sys.argv[1])).read()
# debug = open('debug', 'w')
# debug.write(str(xml))
print_all(xml)